
Uma das proposições de valor da tecnologia Big Data é a capacidade de resolver problemas complexos do cotidiano que, em geral, exigiriam esforços tremendos (pessoas, processos, tecnologia) para proporcionar alguma chance de sucesso. Em vários cenários de negócio, seja na criação fabril de produtos ou execução de serviços, o ganho de escala operacional traz desafios importantes para determinar a capacidade de uma empresa em crescer (ou não) de forma sustentável no longo prazo. Se o custo de produção/operação acelera além do crescimento de receita, certamente há problemas de escala.
A partir deste post, contaremos a jornada de transformação digital de um dos clientes Datenworks e como este cliente, através de Big Data e uso adequado de engenharia de software e automação de processos, reinventou a sua forma de operar, gerar valor para o seu mercado e escalar seu próprio negócio.
Qual o problema?
Imagine que você lidera uma empresa, com mais de 20 anos de mercado, que presta serviços na área de clipping 👇 para mais de 1000 clientes (empresas/pessoas físicas) em todo o Brasil.
Clipping é uma expressão idiomática da língua inglesa, uma “gíria”, que define o processo de selecionar notícias em jornais, revistas, sites e outros meios de comunicação, geralmente impressos, para resultar num apanhado de recortes sobre assuntos de total interesse de quem os coleciona.
Sua oferta de clipping envolve capturar, estruturar e apresentar ao seu cliente, no tempo máximo contratado, todo o nível de exposição da imagem do cliente (pessoa/empresa) e temas de interesse do mesmo em todas as mídias contratadas. Por “mídia”, há de tudo. Jornais (digitais e impressos), revistas, web sites, TV, rádio, etc. De todas as mídias capturadas, uma das mais importantes é conhecida como mídia impressa, que reúne jornais e revistas (digitais e impressos) de todo o país, abrangendo grandes centros e até mesmo pontos mais remotos.
Agora considere o seguinte cenário:
- Pauta diária de leitura de impressos compreende, em média, 300 jornais distintos. 😮
- Jornais distribuídos por todo o Brasil.
- Operação integral, 365 dias por ano.
- Leitura totalmente manual, realizada por dezenas de pessoas 😲
- Os principais jornais do país precisam ser “lidos” (com muita atenção) e entregues para clipping (recorte e envio ao cliente) até às 07:00, todos os dias. 😰
Considerando que sua empresa já realiza esta atividade com alto nível de qualidade mas, ao mesmo tempo, com alto custo operacional (funcionários, espaço físico, etc.), como lidar com o crescimento potencial do seu negócio diante dos claros desafios de escala?
A leitura de impressos, dentre vários aspectos, é uma das operações mais complexas da rotina de clipping. Apenas citando alguns:
- Janela de leitura prioritária — 18 jornais de grande circulação (em média, 800 páginas) lidos até 07:00.
- Em alguns jornais, há mais de uma pessoa realizando a leitura.
- Um dos principais jornais leva mais de 1h para ser lido por 2 (duas) pessoas.
- Pessoas falham (e também faltam ao serviço, eventualmente).
- Hora-extra aos fins de semana.
- Não basta “apenas ler”. É preciso identificar e apontar os termos de interesse de centenas de clientes interessados no conteúdo impresso.
Neste processo, a única forma de ganhar escala de produção é, simplesmente, contratar mais leitores, que precisam ser treinados, escalados em times e acompanhados por gestores, estações de trabalho e planejamento de logística para deslocamento até o escritório da empresa, onde todos estão para o turno de produção.
Muita coisa que pode dar errado, não? 👎
O ponto central da questão envolve ganho de escala na leitura de impressos. Para obter ganho de escala, é preciso isolar da interferência (e dependência) humana as tarefas de alta repetição, sensíveis a erro e que causam degradação e perda de qualidade do processo como um todo, quando falhas ocorrem.
Solução proposta
Há muitos anos, a indústria de tecnologia já pesquisa abordagens com uso de computadores para automação de processos do cotidiano de pessoas, como a leitura de texto em linguagem natural (inglês, português, etc.)
Para o desafio em clipping, a solução passaria por automatizar a leitura a partir de técnicas de OCR (Optical Character Recognition). Há diversas soluções OCR no mercado (comerciais e open-source, cloud e on-premises), mas apenas “ler” não seria o bastante. Como identificar o conteúdo relevante para o cliente final? Diante de um volume gigantesco de informação (300 jornais por dia, lembra?), como fazê-lo no menor tempo possível, sem comprometer a qualidade já alcançada na abordagem manual?
A solução desenvolvida sob medida pela Datenworks, após estudo e definição clara dos objetivos de negócio, envolveu a construção de um serviço automatizado de leitura de impressos, utilizando tecnologias open-source e cloud computing com foco na máxima eficiência do processo e menor TCO possível.
Em linhas gerais o processo de leitura, agora automatizado, é composto de etapas simples de operação porém bastante ágil em entrega de resultados 👇
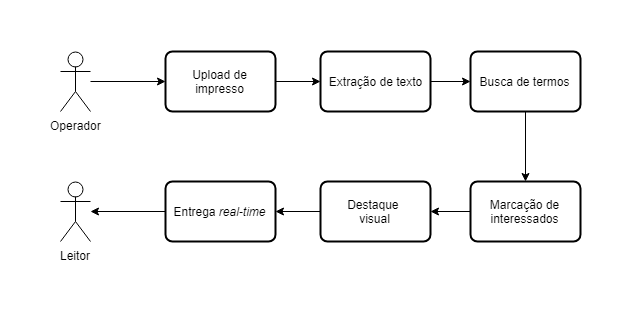
Ao final do processo, os resultados da leitura automatizada são entregues ao leitor de forma que ele apenas faça uma simples revisão, em tempo muito menor do que a leitura manual.
“Mas o que o leitor recebe como resultado?”
A partir de cada página de jornal submetida para processamento, na etapa “Busca de termos”, é realizado o cruzamento de todos o conteúdo de interesse (palavras, frases, filtros, etc) com os termos verificados em cada página, para isolar o conteúdo de interesse de cada cliente e também para destacar o resultado de maneira visual. Dessa forma, uma página “grifada” é entregue assim 👇

A partir do processamento dos metadados de cada página, também é possível destacar termos “hifenizados” no texto, o que aumenta a qualidade da busca e resultado 👇

“Nossa, muito legal! Mas, como isso funciona?”
A arquitetura técnica desta solução utiliza tecnologia open-source e faz uso eficiente de cloud computing, baseado em Amazon Web Services, com foco em high throughput e operação de baixo custo, abordando conceitos como containers, serverless e spot fleet 👇
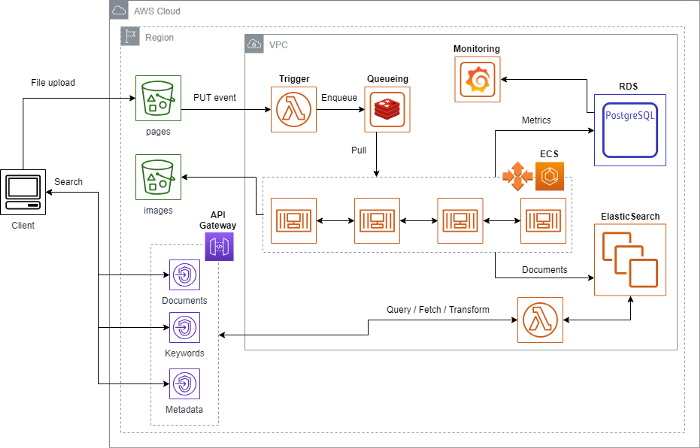
Nesta arquitetura, o uso de Docker containers, AWS Lambda, AWS S3 e AWS API Gateway é bastante explorado como elementos de processamento serverless para o pipeline de leitura de impressos. Para processamento OCR de todos os impressos recebidos, um ECS cluster em spot fleet, utilizando task queueing desenvolvido em Python + ferramentas open-source. Para armazenamento de documentos processados (texto, termos, metadados, etc.) e suporte à busca contextual, um ElasticSearch cluster em alta disponibilidade com políticas de backup automatizadas. Para gestão de configuração e armazenamento de métricas de processo (páginas/palavras verificadas, backlog, etc.), uma instância RDS for Postgresql em modo HA. Para sincronização e entrega dos dados processados (imagens, metadados), API Gateway + Lambda.
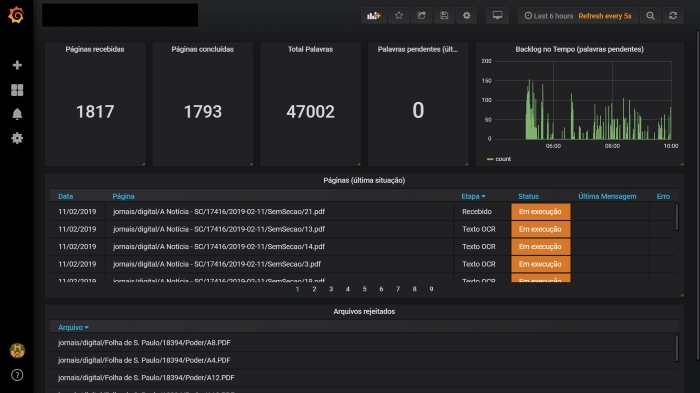
Para monitoramento ostensivo, um dashboard baseado em Grafana para acompanhamento das métricas de processamento em tempo real 👇
“Ok, bem bonito mas, o que a empresa ganhou com tudo isso?”
- Liberação do clipping para os clientes finais, em média, 60% mais rápido.
- Maior quantidade de jornais lidos e revisados.
- Revisão mais ágil e manutenção de alta qualidade de captura de termos.
- Redução de jornada (horas-extras) para produção maior.
- Processo de captura e revisão distribuída (operadores e leitores em home office)
Além dos benefícios ao negócio, alguns números sobre eficiência operacional:
- ~ 4500 páginas processadas por dia
- ~ 300 jornais diários
- Mais de 5GB de dados processados por dia
- Jornal de grande circulação (aquele lido em 1h por duas pessoas) processado e entregue, em média, em 4 minutos
- A operação da plataforma cloud tem custo médio mensal em 40% do rendimento bruto de um único colaborador (leitor)
Como parte de uma série sobre esta jornada, a partir deste, novos posts serão divulgados para detalhar as abordagens técnicas aplicadas nesta solução.
Até mais!
