
Dentro da engenharia de sistemas, é muito complicado fazer o planejamento do desenvolvimento de um produto, pois muitas vezes o desenvolvimento de software é muito mais arte do que ciência, e os projetos falham. Irei descrever como nós da Datenworks projetamos, implementamos e entregamos tecnologia e sistemas.
Antes de mais nada, para não deixar dúvidas, vamos esclarecer o que é o sistema que você verá bastante no texto:
sistema = software + hardware + pessoas.
Desenvolvimento iterativo e incremental
Confiamos, usamos e abusamos dos métodos de desenvolvimento ágil, alinhados com cultura+metodologias DevOps de entrega contínua e aproximamos ao máximo possível o cliente do processo de desenvolvimento do software. Dessa forma, aumentamos a chance de sucesso do projeto, pois trazemos para a mesa a discussão em volta do que realmente agrega valor ao produto.

Prototipação
Muitas vezes nem todos os requisitos para desenvolvimento estão bem descritos, pois nem mesmo o cliente/usuário tem a visão total do que seria necessário fazer para resolver o problema dele. Nesse cenário, muitas vezes é interessante criar protótipos, podendo ser apenas mock-ups ou até mesmo pequenos pedaços de software funcionais para interação.
MVP
Esse conjunto de ideias nos leva muitas vezes a implementação e evolução de Minimum viable products, tendo sempre uma experiência interessante para apresentar ao usuário, colher feedbacks, iterar e melhorar em cima da visão de quem irá utilizar o produto, e não em cima de feeling ou guessing.
Lean manufacturing. Lean Startup. Por que devo me importar?
A metodologia apresentada no livro Lean start-up, descreve bem essas ideias e como elas vêm revolucionando o desenvolvimento de produtos e negócios desde a popularização do Agile Manifesto.
Favorecendo experimentação ao invés de elaborar um plano detalhado, feedbacks dos usuários/clientes ao invés de intuição e um design iterativo ao invés do desenvolvimento prévio de toda a aplicação. Essa metodologia descreve bastante o que o Agile traz para o desenvolvimento de software, porém, com uma visão de negócio/produto e projetos no geral, não se limitando a utilização em softwares.
Um dos pontos interessantes que não podemos ignorar é que: injetar dinheiro no design de um produto não é suficiente para garantir o sucesso desse produto, se ele não estiver usável e for interessante para os usuários.
“Dinheiro não é o problema, pode gastar”

Esse cenário acontece tanto em grandes empresas, quanto em startups que recebem bastante dinheiro em rodadas de investimento e entram numa certa zona de conforto no que diz respeito às tecnologias e o quanto estão dispostas a arriscar.
Muitas vezes o excesso de dinheiro traz confiança para o negócio, e na maioria desses casos, é comum ouvir que “dinheiro não é o problema”. Esse tipo de afirmação traz preocupações como:
- A empresa está abrindo mão de bons desafios técnicos, para se acomodar com algum vendor;
- Está tampando falhas no sistema (tanto software quanto pessoas) com dinheiro, o que não é saudável no médio/longo prazo.
Quando não se consegue contratar a mão-de-obra necessária para operar certo componente (e isso é comum em tecnologia) é aceitável contratar componentes SaaS (software as a service) e terceirizar a operação. Porém, essa falha não pode ser simplesmente esquecida, afinal, cedo ou tarde a conta chega.
Do contrário, será cada vez mais comum o problema de empresas que falharam por ter conforto demais por meio de dinheiro para inovar e deixaram de ganhar potencial competitivo.
Apesar disso ser mais comuns em grandes empresas que têm mais dificuldade para se mover e evoluir, também existe o caso de startups que falharam mesmo recebendo bons investimentos. Apesar de parecer estranho, se apoiar em uma pilha de dinheiro pode ser matador para a criatividade.
Escolha a sua infra como você escolhe comida, não perfume
Há uma frase de um famoso investidor e escritor chamado Benjamin Graham que diz que “Se você estiver comprando ações, escolha-as do jeito que você compra comida, não do jeito que você compra perfume.”
Podemos adaptar essa frase para o nosso contexto dizendo que “se você estiver investindo em sua infra, escolha-as do jeito que você compra comida, não do jeito que você compra perfume”. Afinal de contas, é muito comum ver implementações utilizando ferramentas desnecessárias (over-engineering) para resolver problemas que talvez nunca existam.
Precisamos ser pragmáticos e realistas durante o design de um sistema, o cliente que irá utilizar o software pouco se importa com o que está embaixo dos panos, desde que as requisições estejam sendo respondidas em um bom tempo, e não haja falhas na interação.
Gastar menos combustível, permite que você rode por mais tempo, e chegue mais longe.
A importância das métricas e do monitoramento
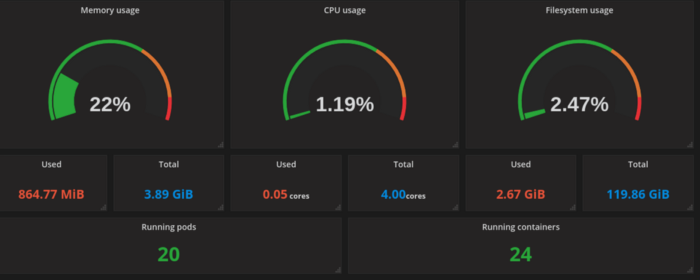
Ter um bom monitoramento configurado, e métricas de consumo dos recursos nos ajuda a ter base para fazer cálculos de carga e capacity planning da infraestrutura. Assim como ajustar pontos de lentidão na aplicação para responder mais rápido e melhor, com métricas de APM.
Ser assertivo e ter uma visão clara da realidade sobre a sua aplicação/produto cria maiores possibilidades de sucesso, ao invés de ser intuitivo.
Agora que a palavra das premissas foi passada, vamos falar do desenvolvimento!
Exemplo prático de produto entregue
A melhor maneira de evidenciar todas essas ideias seria colocar elas em prática. Portanto, vamos ao desenho de um projeto real em que pudemos aplicar tudo o que foi apresentado até aqui, pois de gente que fala que faz o mercado já está cheio.
Seguindo a linha do processamento inteligente de textos, tivemos a oportunidade de fazer a reengenharia de processos de uma empresa de clipping, utilizando RPA para facilitar a operação e dar escala ao processo.
Para fazer o produto “parar de pé” por conta própria, nós projetamos ele para ser:
- Extremamente enxuto, usando apenas componentes que fossem realmente necessários, inclusive em termos de infra, fazendo testes de carga e usando os tamanhos ideais (nem maiores, nem menores) de VMs, e mais da metade da infraestrutura passa menos de 10h por dia ligada;
- Gastamos no máximo 2h por mês com a infra, não há manutenção, o monitoramento não alerta, e não há indisponibilidade devido a implementação de escalabilidade e resiliência na aplicação e na infra;
- Qualquer tarefa/requisição executada pode ser interrompida a qualquer momento e a aplicação garante que ela não será perdida. Na pior hipótese, só é refeita e mesmo assim não cria duplicidade;
Dentro da ideia de produto enxuto, levamos em consideração o Lean desde o modelo Toyota, utilizando dos 3M e Kaizen para abordagem do todo.
Arquitetura proposta
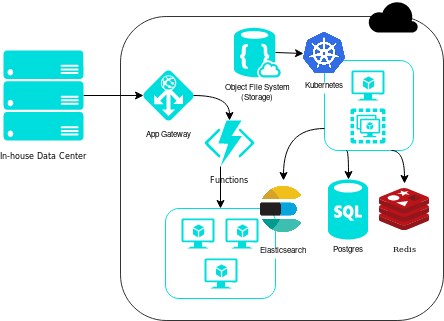
Esse foi o primeiro diagrama de implementação, que já está um pouco distante da realidade. Nesse momento ainda não tínhamos escolhido qual seria o cloud-provider, portanto, o diagrama está com desenhos genéricos (e alguns ícones bonitos do pacote da Azure).
Por que ainda não tínhamos escolhido o cloud-provider? Não queríamos oferecer uma experiência ruim para os usuários, portanto a confiabilidade foi colocada acima dos outros requisitos, como eficiência em custos.
Comparamos Google Cloud Platform e Amazon Web Services, com benchmark de implementação, estimativa de custos e quais features seriam usadas em cada nuvem.
Implementação na nuvem
Escolhemos AWS com a seguinte conclusão (na época):
Olhando apenas para os custos, a GCP se apresenta como o melhor provedor de infraestrutura. Porém, o fato do custo ser mais baixo está diretamente ligado com a falta de maturidade do ambiente, sendo o custo utilizado como estratégia de promoção do provedor. Nesse caso, a confiabilidade fica arriscada, e o comportamento das aplicações não seria tão previsível quanto na AWS.
Outro ponto a ser analisado, é a velocidade para desenvolvimento das aplicações, por ser um provedor mais antigo e estável, a AWS oferece uma velocidade maior no release dos softwares. Além de ter uma comunidade ativa maior, e um suporte mais evoluído em relação aos produtos.
Considerando que os gastos com a AWS ficam 14.67% mais altos em comparação com a GCP, vale a pena utilizar a AWS como provedor, pois a velocidade para o desenvolvimento em uma nuvem mais evoluída, assim como questões claras de segurança, suporte e integridade compensam o custo.
Containers rodando no Kubernetes? Não (:
No primeiro momento a ideia era de utilizar Kubernetes para executar os jobs de processamento dos textos, extração e análise. Porém, percebemos que manter o Kubernetes seria mais trabalhoso do que benéfico (comida, não perfume!) e optamos pelo ECS que, apesar de não ser tão cool nem hype, nos atende bem.
Dentro do ECS temos as definições de services que são executados por meio de auto-scaling groups com instâncias mistas.
Como assim auto-scaling group misto?
Dividimos as instâncias em: 70% spot e 30% on-demand, sendo que a maior parte do tempo, nós estamos consumindo instâncias spot que são maiores que as on-demand.
Essas instâncias on-demand estão lá apenas para garantir que não haja indisponibilidade, caso não tenhamos mais spot instances na zona para usar. Isso nos traz uma economia de aproximadamente 46% nos gastos com EC2.
Sem falar que as instâncias não passam 24h ligadas, elas são apenas ativadas durante as horas de processamento, e ao longo do dia há um script rodando no Lambda que ajusta a quantidade desejada e máxima no auto-scaling, para que o scale down seja mais rápido e sutil.
Nem mesmo o DB fica ligado 24h
Exceto o Redis que precisa estar de pé o dia quase todo, para receber eventos da inserção de novos jornais no S3 (nós desligamos ele, e podemos implementar um fallback pro SQS), toda a infra é desligada fora do horário comercial.
Claro que em outros casos não seria tão simples desligar tudo, isso se dá pela natureza de consumo dos usuários. Porém, acreditamos que sempre há melhorias para serem feitas nos sistemas.
SaaS para tudo? Também não
A única coisa que não está sendo executada em EC2 é o PostgreSQL, pois o RDS nos traz ótimos benefícios por um custo aceitável, ainda mais que instâncias no RDS podem ser desligadas desde 2017.
Isso não nos gera indisponibilidade, nem desconfiança. Software as a Service só se torna uma opção atraente quando não há a capacidade de manter a própria infra na empresa.
Se disponibilidade for a única preocupação, então posso dizer que esse produto está no ar desde Novembro de 2018, e a aplicação se mantém de pé sem manutenção. A implementação da infra está bem confiável, vamos falar de SRE? (:
Simplicidade — a arte de maximizar a quantidade de
trabalho não realizado — é essencial.
Concorda? Discorda? Muito pelo contrário?
Se estiver afim de acrescentar seu ponto ao texto, comenta aí que a gente conversa :D
